
지나공 : 지식을 나누는 공간
[직무인터뷰] JAVA 이야기 - 2편 본문
자주 나오는 질문이라고 들은 건 형광펜 표시했습니다.
대답에 꼭 들어가야 하는 키워드는 컬러펜 표시했습니다.
1번 질문에 대한 꼬리질문은 1-1, 1-2와 같이 정리합니다.
[질문의 목차]
- 인터페이스와 추상클래스의 차이가 뭔가?
- 각각의 존재 이유는 뭔가?
- 팩토리메소드패턴이 뭔가?
- Mutable Immutable 이란 무엇인가?
- 대표적인 예시를 들어봐라
- 그게 왜 Immutable인지 설명할 수 있는가?
- 그럼 그걸 Mutable 하게 쓰고 싶다면 어떻게 해야 하는가?
- synchronized가 뭔가?
- 기본형을 참조형으로 쓰는 방법은?
- 제네릭이 뭐고 왜 쓰나?
- 접근 제어자와 범위를 말해봐라.
1. 인터페이스와 추상클래스 차이 (자주 나옴) / 존재이유!!
인터페이스는 쉽게 말하면 껍데기. 설계도라고 생각하면 된다.
모든 메소드가 추상메소드이고, 일반 변수를 가질 수 없다.
다중상속이 가능하다.
생성자를 가질 수 없다.
인터페이스는 final을 붙일 수 없고 내부 변수가 모두 static이어야 한다.
하나 이상의 인터페이스를 상속할 수 있는데 여러 개일 때는 콤마를 사용하고 이때는 클래스에서 상속받는 게 아니라 인터페이스를 상속받는 거니까 내용이 없는 메소드들을 그대로 둔다. 이건 새로 구현하는 게 아니니까 일반 클래스끼리 상속 받는 것처럼 extends 를 사용한다.
interface Vehicle(){
abstract void run();
abstract void move();
}
추상클래스는 미완성 설계도다.
클래스 내에 추상메소드가 없거나 하나라도 포함되어 있는 클래스다. (추상메소드는 abstrac가 붙은 메소드)
클래스 내에 메소드가 단 하나라도 추상메소드라면 그 클래스 앞에 반드시 abstract를 붙여야 하고, abstract와 final은 동시에 표기할 수 없다.
일반 메소드나 일반 변수를 가질 수 있다.
생성자를 가질 수 있다.
존재 목적은 상속 받기 위함이다. -> extends
추상클래스를 추상클래스가 상속받으면 추상메소드를 모두 구현하지 않아도 되지만, 일반 클래스가 상속받으면 추상메소드를 모두 구현해야 한다.
abstract class Animal {
abstract void bark();
void feed() {
...
}
}
더 이야기를 하자면, 인터페이스와 추상 클래스는 존재 목적이 다르다.
//추상클래스
abstrac class Shape
{
abstract void draw();
void hit(int x){
x = 3;
}
}
//인터페이스
interface Shape
{
void draw(); //모두 추상메소드여야 하고, abstarct 생략 가능
abstract void move(int x);
}
//abstract 메소드는 구현체가 없으니 {}도 없다.
//abstract 클래스를 상속
class Triangle extends Shape{
void draw(){
System.out.println("삼각형을 그린다.");
}
//hit은 재정의하거나 그냥 부모 클래스에 있는 그대로 써도 된다. 일반클래스니까.
}
//interface 상속
class Triangle implements Shape{
public void draw(){
System.out.println("삼각형을 그린다.");
}
public void move(int x){
System.out.println("삼각형을 이동시킨다.");
}
}
추상 클래스는 상속받아서 기능을 이용하거나 확장시키는 목적이고, 인터페이스는 함수의 껍데기만 있는데 이 함수들의 구현을 강제로 하게 하기 위해서이다.
인터페이스 :
하나의 규약, 즉 구체적인 약속 같은 것으로 인해 협업에 필수적이다.
큰 프로젝트이거나 개발인원이 많을 수록 인터페이스를 통해 많은 이점을 얻게 된다.
추상클래스 :
상속을 강제하기 위해서다.
부모 클래스에서는 정의만 해놓고 실제 동작은 자식 클래스에서 하게 되는데, 이런 추상클래스의 성격이 잘 반영된 것이 팩토리 메소드 패턴이다.
1-1. 팩토리 메소드 패턴은 뭔가?
어떤 상황에서 조건에 따라 객체를 다르게 생성해야 할 때가 있는데 이렇게 조건을 분기해서 객체를 생성하는 것을 직접하지 않고 팩토리라는 클래스에 위임해서, 팩토리 클래스가 객체를 생성하게 하는 방식이다.
일단 어느 상황에서 필요한지부터 보자.
public abstract class Type{
}
public class TypeA extends Type{
public TypeA(){
System.out.println("Type A 생성");
}
}
public class TypeB extends Type{
public TypeB(){
System.out.println("Type B 생성");
}
}
public class TypeC extends Type{
public TypeC(){
System.out.println("Type C 생성");
}
}
//createType 메소드를 통해 String 에 따라 분기해서 class를 생성
public class ClassA {
public Type createType(String type){
Type returnType = null;
switch (type){
case "A":
returnType = new TypeA();
break;
case "B":
returnType = new TypeB();
break;
case "C":
returnType = new TypeC();
break;
}
return returnType;
}
}
public class Client {
public static void main(String args[]){
ClassA classA = new ClassA();
classA.createType("A");
classA.createType("C");
}
}위의 상태를 보면 classA에서 createType 메소드가 인수로 들어온 type에 따라 분기해서 class를 생성하고 있다.
근데 이 일을 만약 여러 클래스에서 해야 한다면, classA외에도 classB, classC를 만들어서 각각에서 또 같은 코드를 작성해서 조건 분기에 따른 클래스 생성 메소드를 만들어야 한다. 그러면 중복 코드가 발생할 것이고 유지 보수도 어렵게 된다.

그래서 팩토리메소드패턴을 사용하여, 분기에 따라 객체를 생성하는 일을 자기 자신의 클래스에서 하지말고 하나의 팩토리 클래스로 만들어버리는 것이다. 그러면 ClassA, ClassB 등에서 분기 객체 생성을 통한 일을 해야할 때 해당 메소드를 각각 가지고 있을 필요가 없어진다. 그냥 팩토리 클래스를 하나 만들고 그걸로 객체 메소드 호출만 하면 된다.
public class TypeFactory {
public Type createType(String type){
Type returnType = null;
switch (type){
case "A":
returnType = new TypeA();
break;
case "B":
returnType = new TypeB();
break;
case "C":
returnType = new TypeC();
break;
}
return returnType;
}
}
public class ClassA {
public Type createType(String type){
TypeFactory factory = new TypeFactory();
Type returnType = factory.createType(type);
return returnType;
}
}
이걸 왜 쓰는가?
클래스 객체의 생성과 사용의 러리 로직을 분리해서 결합도를 낮추기 위해서이다.
결합도를 낮추어 직접 객체를 생성해서 사용하지 않고 서브 클래스에게 생성 클래스 로직을 위임하면 효율적으로 코드를 제어할 수 있다.
2. Mutable, Immutable 객체가 뭔가?
Mutable (가변객체) : 프로그램이 실행되면서 값이나 상태가 변경되는 객체.
Immutable (불변객체) : 생성 시점부터 내부 상태가 일정하게 유지되어 프로그램 실행 중에 변경되지 않는 객체.
int, double, char 이런 것들은 다 mutable이다.
String은 전형적인 Immutable 객체다. / final 변수도 immutable이다.
2-1. Final ArrayList<String> list = new ArrayList<String>(); 으로 했을 때 list에 데이터 추가가 가능한가?
당연히 데이터 추가가 가능하다. final을 붙였으니 불변객체인데 뭐지 뭐지... 할 수 있는데, 여기서 final은 리스트의 주솟값이 고정된거지 그 리스트에 들어가는 데이터를 못 바꾼다는 게 아니다. ArrayList를 선언한 건 어떤 특정 주솟값을 고정시키고 그 값에 쭉 값을 연결한다는 의미고, 여기서 new ArrayList를 만들면 잘못된거지만 이 해당 주솟값에 데이터를 쭉 연결하는 건 당연히 가능하다.
2-2. String 이 왜 Immutable인가?
String Pool :
어떤 특정한 공간에 데이터가 오면 차곡차곡 쌓고 그 데이터를 참조할 수 있게 만드는 것. 힙 영역에 있다.
자바의 String 객체는 특별히 이 String constant pool에서 따로 관리된다.

위 그림처럼 int 변수인 num은 스택 메모리에 값을 바로 저장하고 있어서 이 값이 변경되면 그냥 변수가 갖고 있는 메모리에서 값을 변경한다. 이미 할당된 메모리는 변하지 않고 값이 변경되니까 가변인 것이다.
반면 String 변수 str은 일단 애초에 stack에 주소만 저장되고 실제 데이터가 heap 중에서 String constant pool에 저장된다. 그러다가 str의 값을 변경하면, 기존 값 "abc"가 저장되어 있는 string constant pool내의 메모리는 그대로 있고, 새 값 "def"가 pool에 생기면서 str이 참조하는 주솟값이 "def"의 주솟값으로 변경된다.
더 이해를 하기 위해 아래와 같은 상황에서 s1과 s2에 대해 생각해보자.
String s1 = "Cat";
String s2 = "Cat";

우리의 예상은 s1, s2가 둘다 "Cat"이더라도 다른 변수니까 다른 주소에 할당될 것 같은 느낌이다. 하지만 실제로는 같은 문자열이면 같은 주소를 가리키게 된다. Java가 실행될 때 String Pool안에 있는지 확인한 다음 기존 값이 있으면 그걸 가리키게 한다. 그래서 s1 == s2 를 따지면 true다.
아, 물론 여기서 말하는 ==는 값이 아니라 주솟값을 말하는 것이다. String은 참조형변수(reference type)여서 주솟값 비교는 ==을 통해 가능하고, equals를 사용해야 주소말고 실제 문자열을 비교하는 것이다. 하튼 s1과 s2는 같은 주소를 가리킨다.
그런데 이 상황에서 아래 코드를 추가한다고 가정하자.
String s1 = "Cat";
String s2 = "Cat";
String s3 = new String("Cat");이렇게 new를 사용하면 무조건 이 "Cat"을 새로 만들어줘! 라는 의미이다. 그래서 s3는 String pool이 아닌 힙 영역 내 다른 주소값에 할당된다. 여기서 s1 == s3를 구하면 false다.
2-2-1. String을 왜 불변으로 할까?
이로 인해 얻는 장점이 있다.
1. String constant pool이 있기에 자바 런타임에서 힙 영역의 메모리를 절약할 수 있다. 같은 값을 갖는 String에 대해 같은 메모리를 참조하게 할 수 있기 때문이다. 만약 String이 가변이었다면 해당 메모리의 값이 언제 바뀔지 알 수 없으니 String pool의 형태로 관리할 수 없다. 예를 들어 a,b,c라는 String 변수가 모두 같은 메모리를 가리킬 때 a의 값을 바꾸면 b와 c의 값도 바뀌는 문제가 발생한다. 이렇기에 불변이어야 String pool의 형태로 관리할 수 있다.
2. String이 불변이면 멀티 쓰레딩 환경에서 안전하다. 값이 불변이기 때문에 멀티쓰레딩 환경에서의 동기화 문제를 걱정할 필요 없다. (가변 값은 동시에 접근해서 어떤 쓰레드가 값을 사용 중인데 그 사이 또 다른 쓰레드가 값에 변화를 주었을 때 문제가 발생한다.)
2-3. String을 어떻게 하면 Mutable(가변)하게 쓸 수 있는가?
String Builder와 String Buffer.
그냥 string에 concat하고 덧셈연산하고 그러면 되는 거 아닌가요? 라고 묻는 사람이 있을텐데, 불변인 일반 String을 계속 쓰면 힙에 있는 String pool에 값이 계속 쌓일 것이다. String 의 덧셈연산을 계에에속 하면 string pool 커지면서 메모리가 터지고 프로그램이 죽는다. 그러니 String Builder와 String Buffer를 써야 한다.
얘네를 쓰면 string을 수정할 때 그 자리에서 string값이 실제로 수정된다.
특히, 스레드랑 관련이 있으면 StringBuffer를 쓰고, 스레드 안전여부와 상관 없는 환경이면 StringBuilder를 사용하는 게 좋다.
2-3-1. String Builder와 String Buffer의 차이는?
동기화의 유무 차이이다.
StringBuffer는 synchronized 키워드가 존재해서, 멀티스레드 환경에서도 동기화를 지원한다.
StringBilder는 동기화를 보장하지 않는다.
따라서 단일스레드 환경이면 StringBuilder를 사용하고, 멀티스레드는 StringBuffer를 사용하는 게 좋다.
물론 단일스레드에서 StringBuffer를 써도 되긴 하지만 동기화 관련 처리로 인해 StringBuilder보다 성능이 좋지 않다.
2-3-2. 그럼 synchronized가 뭐냐?
하나의 자원(데이터)에 대해 여러 스레드가 사용하려고 할 때 한 시점에서는 하나의 스레드만 사용할 수 있도록 보장하는 것.
3. 자바의 자료형에 대해서 이야기 해봐라.
Java의 기본자료형(primitive)과 참조자료형(reference)
- Primitive type(기본형) : int, char, long, double...
- Reference type(참조형) : Class, Interface, Array...
3-1. Primitive type을 Reference type으로 사용하는 방법은?
Integer, Long, Double 등의 java 라이브러리에 선언된 데이터 타입을 사용하면 된다.
4. Java에서 int 값을 call by reference로 전달하는 방법은?
답은, int를 Integer 타입으로 보내면 된다.
Call by value & Call by reference에 대해 알아야 한다.
기본 자료형은 call by value, 참조 자료형은 자동으로 call by reference로 동작한다. (c언어랑은 다르다 좀)
5. Generic이 뭔가?
클래스에서 사용할 타입을 클래스 외부에서 설정하는 것이다.
ArrayList list = new ArrayList<String>(); string의 자리가 T다. 이 꺽새 안에 넣은 타입을 가지고 쭉 연산을 하는 것이 제네릭이다. 또, 제네릭의 타입으로는 참조형 데이터 타입만 설정 가능하다.
5-1. 이걸 왜 쓸까?
이 리스트에는 무조건 T의 타입만 들어가야 한다고 선언을 했다고 가정하자. 그래서 코딩하면서 T 타입의 연산만 쭉 넣었어. 그런데 개발하던 도중에 뭘 잘못해서 T가 아닌 다른 타입의 값이 들어갔다고 했을 때, 이것에 대해 프로그램이 실제 실행될 때 오류를 잡는 게 아니라 컴파일 단계에서 미리 오류를 알 수 있게 한다.
6. 접근 제어자를 각각 말하고 이게 각각 어디까지 접근 가능한건지 말해봐라
private : 같은 클래스 내에서만 접근 가능
-> 캡슐화에 맞게 외부에서 함수 내부로 접근 못하게 하려고 보통 쓰는 접근 제어자.
default : 같은 패키지 내에서만 접근 가능 (변수나 메소드, 클래스 앞에 아무것도 안 쓴 경우)
protected : 같은 패키지 내 혹은 다른 패키지의 자식 클래스에서 접근 가능
//protected 예제
package front;
public class One{
protected String one;
protected String getOne(){
one = "one";
return one;
}
}
package model;
import front.One;
public class Main{
public static void main(String [] args){
One a = new One();
System.out.println(a.one); //에러
System.out.println(a.getOne()); //에러
}
} 위와 같이 작성하면 에러가 발생한다.
아래처럼 수정해야 한다.
package model;
import front.One;
public class Main extends One {
public static void main(String [] args){
Main main = new Main();
System.out.println(main.one); //정상
System.out.println(main.getOne()); //정상
}
}
public : 모두 접근 가능
접근제어자를 사용하는 이유는 클래스 내부에 선언된 데이터를 보호하기 위해서이다.
외부에서 함부로 데이터를 변경하지 못하도록 외부로부터 접근을 제어하고, 이러한 데이터 감추기를 캡슐화라고 한다.
컬렉션 프레임워크란?
다수의 데이터를 쉽게 처리할 수 있게 표준화된 방법을 제공하는 클래스 집합이다.
ArrayList와 LinkedList의 차이는?
ArrayList는 데이터 추가/삭제 시 임시 배열을 생성해서 데이터를 복사하고 데이터별로 인덱스가 있어서 검색에 유리하다. 하지만 LinkedList는 자신의 앞뒤 노드만 인지하는 상태라서 인덱스가 없고 모든 노드를 순회해야 하니 검색에 불리하다. 하지만 데이터 추가/삭제 시에 불필요한 데이터 복사과정이 없어서 좋다.
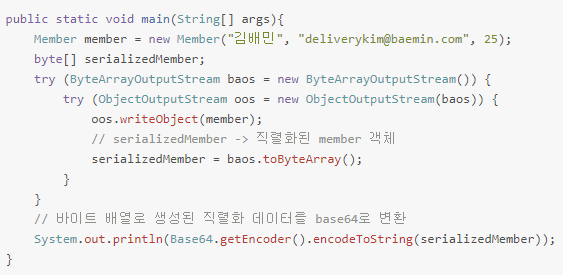
직렬화란?
자바 시스템 내부에서 사용되는 객체나 데이터를 외부의 자바 시스템에서도 사용할 수 있게 byte형태로 변환하는 것이다. JVM의 메모리 힙이나 스택에 상주되어 있는 객체 데이터를 바이트 형태로 변환한다.
스트림이 뭔데?

자바에서는 파일이나 콘솔의 입출력을 직접 다루지 않고 스트림이라는 흐름을 통해 다룬다.
즉, 스트림은 운영체제에 의해 생성되는 가상의 연결 고리를 의미하고, 중간 매개자 역할을 한다.
여기서의 스트림은 자바8에 추가된 스트림 api와는 다른 스트림이다.

json이 뭔가?
JSON은 경량의 데이터 교환방식이다. 특정 언어에 종속되지 않고 대부분의 프로그래밍 언어에서 json 포맷의 데이터를 핸들링할 수 있는 라이브러리를 제공한다.

직렬화 어디 쓰이는가?
캐시나 자바 RMI에 쓰인다.
자바 RMI(Remote Method Invocation)는?
분산되어 있는 객체 간의 메시지 전송이나 메소드 호출을 가능하게 하는 프로토콜이다.
네트워크로 연결되어 있는 다르 컴퓨터에 존재하는 메소드를 마치 내 컴퓨터에 있는 것처럼 호출해서 사용 가능하게 한다.
serialVersionUID가 왜 필요한가?
JVM은 직렬화와 역직렬화를 하는 시점의 클래스에 대한 버전 번호를 부여한다. 만약 중간에 클래스의 정의가 바뀌었다면(속성 추가 등등) 새로운 버전 번호를 할당한다. 그래서 직렬화할 때의 버전번호가 역직렬화할 때의 버전번호와 다르다면 역직렬화가 불가능하게 될 수 있다.

참고 : http://alecture.blogspot.com/2011/05/abstract-class-interface.html / https://mygumi.tistory.com/264 / https://victorydntmd.tistory.com/299 / https://readystory.tistory.com/141?category=784159
'Tech Interview' 카테고리의 다른 글
| [직무인터뷰] JPA 이야기 (1) | 2021.06.07 |
|---|---|
| [직무인터뷰] Spring과 DB 이야기 - 2편 (0) | 2021.06.06 |
| [직무인터뷰] Spring과 DB 이야기 - 1편 (2) | 2021.06.05 |
| [직무인터뷰] 네트워크 이야기 (0) | 2021.05.21 |
| [직무인터뷰] JAVA 이야기 - 1편 (4) | 2021.05.19 |



